![]()
![]()
![]()
![]()
![]()
by Billy Barron
Gopher originally made a name for itself by being a simple, fast, reliable, and powerful protocol. However, the original version of Gopher (designed in 1990) ran out of steam for new features after only two years of existence. The protocol has been
upgraded, with numerous gateways to work around the problems and limitations of Gopher. Also, many tools have been written to better manage Gopher.
The result is that Gopher is now simple for the user, but it can be complex if you look deep enough. Much of the complexity can be utilized only by a guru. In this chapter, I hope to give you the background needed to become a Gopher guru and to show off
some of the tricks that gurus use with Gopher.
The original version of the Gopher protocol is now known as the Gopher0 protocol. It is important for the guru to understand the basic protocol especially when writing or debugging clients, gateways and servers, but it is also useful in understanding
how Gopher works and how to create links between Gophers.
Before looking at the protocol syntax, it is important to remember that all Gopher items have a Host, IP Port Number, Path, Type, and Name. The Host and IP Port define where the Gopher server is that has the item on the Internet. The Path tells where
that item is on that Gopher server. The Type tells what type the item is. This is similar to a file type and is documented in Table 18.1. The Name is the name of the item as it should appear on the screen.
Type |
Meaning |
|
0 |
ASCII file |
|
1 |
Directory |
|
2 |
PH phone-book server |
|
3 |
Error |
|
4 |
Binhexed Macintosh file |
|
5 |
DOS binary archive |
|
6 |
UUencoded file |
|
7 |
Index-Search item (WAIS, and so on) |
|
8 |
Telnet |
|
9 |
Binary file |
|
+ |
Redundant server (never implemented) |
|
g |
GIF |
|
I |
Image file |
|
T |
TN3270 |
The actual protocol is very simple. The client connects to the server and then requests a path name, followed by a <CR><LF>. The server then returns the item. When the server finishes sending the item, it closes the connection.
If the item being returned is a menu, then the following syntax is used with one menu entry per line:
Type<TAB>Name<TAB>Path<TAB>Hostname<TAB>Port<CR><LF>
The important variation on this syntax is that <CR><LF> may optionally be replaced by a <TAB> followed by some more data. This will be important when we talk about Gopher+. Gopher0 clients, however, should just ignore the additional
data beyond that <TAB>. The client then uses the information to display a menu to the user.
You should have noticed that Gopher will open and close a connection for every item the client wants to see, instead of maintaining a static connection like some protocols (such as FTP). One of the effects of this is that the server keeps no memory of
what the client has done previously. This is known as being a stateless server.
The effects of this design choice are very important to comprehend, if you are trying to become a guru. On the positive side, the server is very low overhead and is a much simpler program than if it kept state. The negative aspects are that the opening
and closing of connections can be slow at times, and the lack of state makes implementing some features very difficult. Even so, Gopher tends to be very responsive, and the Gopher server uses little system resources.
The Gopher0 protocol has served its purpose well and continues to do so. By mid-1992, though, it became apparent that Gopher had some limitations and could not handle some of the demands being placed on it. The Gopher Team at University of Minnesota
(UMN) designed a new version of the Gopher protocol called Gopher+ to meet these demands. Some of the features that were added in were forms, identifcation of server adminstrators, password protection on selected items, and alternative views of a document.
One of the important design criteria of Gopher+ was that it be totally compatible with Gopher0—so compatible that Gopher+ clients could talk to Gopher0 servers and Gopher0 clients could talk to Gopher+ servers, with no changes to the Gopher0
software. Unfortunately, while the Gopher+ protocol meets this design goal, it is not as clean-cut and simple as the basic Gopher protocol.
Gopher servers return information in the following format if Gopher+ information is associated with the item instead of the Gopher0 format given previously:
Type<TAB>Name<TAB>Path<TAB>Hostname<TAB>Port<TAB><+>Gopher+ Information
Gopher+ also has some error-handling features in the protocol, but this section ignores them; usually, only client-and-server authors need to know this part of the protocol. This section focuses instead on the most important feature of Gopher+, which is
attributes.
Every Gopher+ item has at least two attributes associated with it, although in theory it can have an infinite number. Each attribute has an attribute block that describes it. Normally, the client does not see the attributes unless it specifically asks
for them. The client requests them by adding a TAB and a ! to the end of the request to get all of them, as in the following:
0Welcome to Texas Metronet <TAB>!
At times, however, the client may be interested in only some attributes. In that case, include the TAB and the !, then add a + and the name of the attribute. Some sample attribute blocks might look like the following:
+INFO: 0Welcome to Texas Metronet<TAB>howdy<TAB>metronet.com<TAB>70<TAB>+ +ADMIN: Admin: Mart Hacker <hacker@metronet.com> Mod-Date: 1 July 1994 <19940701133333> +VIEWS: Text: <5K> Postscript: <10K> Image/GIF: <7K> +ABSTRACT: This is the Texas Metronet Welcome document.
In this attribute block, the INFO block gives the Gopher descriptor string. INFO is a required attribute for all Gopher+ items and must come first.
Next is the ADMIN block, which contains adminstrative information. It is also required for every Gopher+ item and must contain at least the ADMIN and the Mod-Date, for Modification Date, fields. The ADMIN field contains someone who you can complain to
if there is a problem with the item. The Mod-Date lets you know when the item was last updated. The Mod-Date first contains a human-readable form, and then the date in a machine-readable format of YYYYMMDDhhmmss where YYYY is the year,
MM is the month, DD is the day, hh is the hour, mm is the minute, and ss is the second. Other fields that may show up here include Score (used by WAIS searches), Score-range, Site, Organization, Location, Geographic, Time
Zone, Provider, and Author (though these tend to be used infrequently).
The VIEWS block is very important. It allows a document to be available in multiple format with the client picking the format it wants. This block tells the client which formats or views are available and the file size of each. In the previous example,
the document is available as a text file, Postscript, or a GIF image file. The views are described as MIME content types.
The ABSTRACT attribute block allows an item to contain a short abstract. This helps the Gopher user see what the document is about before downloading it. Unfortunately, this item is used rarely.
This section discusses tricks commonly used by Gopher gurus in using Gopher clients. It attempts to be as client-independent as possible. However, because many gurus are UNIX users and the UMN UNIX Gopher client is probably the most common Gopher client
in use, this section covers it while showing tricks that can be performed by Gopher clients. If you are using another client, you will need to try to figure out how to do the equivalent with your client. However, some clients may not have some of the
features discussed. Your only choices at that point are to live without the feature or to install another client package. In addition, if you are using an old version of the UMN UNIX Gopher client, some features may not be available. If so, you may want to
upgrade to the latest version.
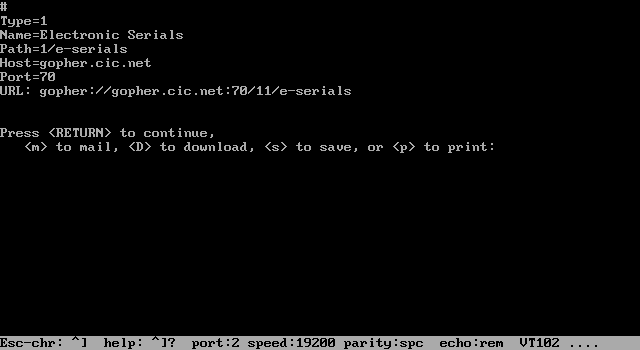
With Gopher, it is easy to start off locally but then, without realizing it, end up looking at something halfway around the world. Many clients give you the ability to find out where you at any given moment (see Figure 18.1). In the UMN UNIX Gopher
client, this feature is invoked by typing the equal sign (=).
Figure 18.1. The UMN UNIX Gopher display of where you are.
In this display, the lines starting with # are comments and unimportant to Gopher itself. The Name= line is the name of the item on the current menu. The Path= is the path used by the Gopher protocol. The Host= line is the hostname that the server is
running on. Port= is the port number the server is running on. Finally, the URL line is Uniform Resource Locator (URL), which describes how to find this item on the Internet in a compact form. URLs are discussed in detail in Chapter 10, "World Wide
Web." Feel free to jump ahead and read it; later sections of this chapter use some URLs.
Frequently when using Gopher, you are somewhere that you want to come back to later. Of course, you could just write down the information about where you are and then tell Gopher to go there again. However, it is much simpler to do this using a feature
called a bookmark. A bookmark is exactly the same as a paper bookmark.
Using the UMN UNIX Gopher client, you highlight the item you want to make a bookmark for and then type a. You will be requested to enter a name for the bookmark. Then if you later type v, a menu of bookmarks will appear, and you can select which
bookmark you want and go right back to that item.
If you are a heavy user of the bookmark feature, from time to time you may want to clean up some old bookmarks that you no longer need. In the UMN UNIX Gopher client, this is easily accomplished by typing d while looking at the bookmark you want to
delete.
In some of the recent releases of Gopher 2.X, a feature known as AFTP is present. AFTP stands for Anonymous FTP. It basically enables you to use your Gopher client as an FTP client instead of using FTP directly. In many cases, using Gopher is much
easier and faster than using FTP directly.
To use AFTP, just type f in the UMN UNIX Gopher client. You will be prompted for an anonymous FTP node name, and then (optionally) a selector string. This selector is the path you want to see on the anonymous FTP server. If you do not specify one, you
will see the top-level directory of the FTP server.
The major disadvantage to this is that it is resource-intensive and does add some load to your Gopher server. This is because AFTP uses your home Gopher server to handle the FTP requests. Also, Gopher is unable to handle some FTP sites that run unusual
versions of the FTP server.
Your Gopher client most likely has quite a few useful configuration options. One of the most important is the ability to define external viewers to use. The Gopher philosophy is to keep the client software as simple as possible. To accomplish this goal,
Gopher needs to call other applications when performing operations such as display graphics, looking at a WWW document, and connecting to remote sites for login.
Also, bookmarks are actually part of your client configuration too. On UNIX, all of these configurations (including the bookmarks) can be found in a file called .gopherrc. An example .gopherrc can be seen in Listing 18.1.
RCversion: 1.1 map: Text,more %s,lpr %s map: Text/plain,more %s,lpr %s map: Audio/basic,play -v 40 -, map: Image,xv %s &,lpr %s map: Terminal/telnet,telnet %s, map: Terminal/tn3270,tn3270 %s, map: text/html,lynx %s, map: Image/GIF,xv %s, map: Image/PCX,xv %s, SearchBolding: no bookmarks: # Type=7 Name=Search for Files Path=7 Host=rodent.cis.umn.edu Port=11111 # Type=1 Name=Electronic Journals (via CICNet) Path=1/e-serials Host=gopher.cic.net Port=70
The RCVersion line is used to specify what format this RC file is in. The map lines specify MIME context types which we discussed while talking about attribute blocks and how to view and print that item type. The context types are generated on the
Gopher server based on the file extension. The %s in the viewer or printer command section includes the filename of the item automatically into the command. The SearchBolding option controls whether or not the text found by a search is bolded. Finally, the
last few lines are bookmarks to items in Gopherspace.
In the UMN UNIX Gopher client, all of these configuration parameters can be set by using the Bookmarks feature and the O command. Other Gopher clients have similar features.
An important part of correctly viewing different types of items is to install a good set of external viewers. Look in Chapter 10 for the location of many useful viewers. Others are available, but they will require you to do some research to decide what
you want and which product to select.
Although Gopher servers are easy to install, some of them also contain quite a bit of powerful functionality that can be exploited only by a guru. In addition, running a server often means using some external utilities to accomplish some tasks that the
server can not perform on its own.
The most common Gopher server in existence is the UMN UNIX Gopher server, which runs on UNIX or VMS. It is fully featured and tracks the leading edge of the Gopher world, including Gopher+. It is highly configurable but easy to install, and it has
excellent performance. Some new versions, however, tend to have occasional bugs. The main negative of this package is that version 2.X is not free to commercial companies. Version 1.13 is freely available, but it does not support Gopher+ and has at least
one serious bug (and several minor ones). The current version can be found as the following:
ftp://boombox.micro.umn.edu/pub/gopher/Unix/gopher2.016.tar.Z.
The VMN Gopher server's main competitor is GN, by John Franks. GN was written in response to the commercialization of Gopher 2.X and therefore is freely available to everyone. GN does not, however, support Gopher+ or many other advanced features. On the
other hand, it can also act as a WWW server—a useful feature if you want to run only one server to handle both your Gopher and WWW needs. It can be acquired from the following directory:
ftp://boombox.micro.umn.edu/pub/gopher/Unix/gn
UMN has also written a Gopher server for the Macintosh. It is known as GopherSurfer. GopherSurfer is good for low-end Gopher server needs. It tracks the latest Gopher features fairly closely. However, it is not freely available for commercial companies.
GopherSurfer is available from the following:
ftp://boombox.micro.umn.edu/pub/gopher/Mac_server
There are two major PC Gopher servers. One is GO4HAM for MS-Windows. It requires a TCP/IP package that supports WINSOCK.DLL. GO4HAM is available from:
ftp://ftp.informatik.uni-hamburg.de/pub/net/gopher/pc/go4ham
The other Gopher is based on the KA9Q software, which is in the public domain and runs under MS-DOS. It is available from:
ftp://boombox.micro.umn.edu/pub/gopher/PC_server/ka9q
Many servers for other platforms exist too. Several of them can be found with a little bit of searching in
ftp://boombox.micro.umn.edu/pub/gopher
It is often useful to make a copy of a menu from a remote Gopher server. The major benefits include increased speed, increased reliability, and less load on the remote Gopher server. At least two different scripts for doing this exist: GopherClone and
MetaClone. With either package, you change to the appropiate directory on your server. Then you enter the name of the script, followed by the URL. It will then make a Gopher menus on the remote server starting at the URL and recursively copying submenus.
Both GopherClone and MetaClone are available in the following directory:
ftp://boombox.micro.umn.edu/pub/gopher/Unix/GopherTools
Forms supported by the Gopher server require using the ASK block facility. On the UMN UNIX server, you need to create a file with a .ask extension. This file will contain the form itself defined in the Gopher ASK block language. For example, a basic
form may look like:
Note: Please enter your last name Ask: Last Name:
This example form requests your last name. After getting the last name, the server looks for a script file that will have the same filename but without the .ask extension. This script file will then get the values entered by the user via standard input.
The script needs to carefully check to make sure that the input will not cause a security problem and then perform the needed processing. The needed processing can be just about anything, from sending an e-mail message to entering data into a database to
giving the user requested information.
The client sees an ASK block by requesting the ASK attribute block by the Gopher+ protocol.To use Gopher forms, therefore, a Gopher+ server and client must be used. A later section, "Forms Gateway," discusses a forms gateway that will get
around this requirement.
Some Gopher adminstrators have problems with their Gopher server dying every once in a while. It can be very embarrasing; the users tend to see that it is down before the adminstrator does. Fortunately, a piece of software named Shepherd exists and can
be acquired from the following:
ftp://boombox.micro.umn.edu/pub/gopher/Unix/GopherTools/shepherd1.0.tar
Shepherd detects that the Gopher server is down and automatically restarts it. In fact, Shepherd can do the same for HTTP (HyperText Transfer Protocol) and other such servers.
At one time or another, many Gopher gurus have decided to organize Gopherspace into subject-oriented menus. As has been repeatedly proven, Gopherspace is too large and grows too fast for any person working part-time to even begin to stand a chance to do
it. Even someone working full-time on it for pay would have a hard time doing it.
However, the guru still has a couple of options. One is to search for subject-oriented lists created by other people and provide links to as many of these as possible. The downside to this approach is that the users have to search multiple subject
directories to find information on one topic.
Another alternative is a program called LinkMerge. LinkMerge downloads the menus from various places that have menus on the same topic. Then LinkMerge merges the menus together to form one menu. This gets over the downside of the previous approach. To
use LinkMerge effectively, the Gopher adminstrator needs to develop a list of other Gophers strong in particular topics (although a decent list is included with the LinkMerge package). Then on a periodic basis, the administrator needs to run LinkMerge,
preferably late at night, to update the menus because, as you know, Gopherspace changes frequently. LinkMerge is available as:
ftp://boombox.micro.umn.edu/pub/gopher/Unix/GopherTools/linkmerge0.1.shar
In addition to accessing the data types that are natively supported in Gopher, Gopher provides some mechanisms to access other data types such as other Internet services, databases, and even Usenet News. These mechanisms are typically called
gateways. Gopher is flexible and offers many different ways for these gateways to be implemented and interface with Gopher.
One of the older approaches is to implement a server that talks the Gopher protocol but provides the needed service. More recently, the go4gw server was designed. The go4gw server sits on an IP port and talks the Gopher protocol (recent versions even
talk the Gopher+ protocol). The go4gw server has an API (Application Programming Interface) that can be used by programs. Several people have written interface modules that use the API to tie various services into Gopher.
If you are interested in writing your own interface module, the best way to learn is to look at some of the sample Perl programs included with the go4gw software. Speaking of which, the software is available from the following:
ftp://boombox.micro.umn.edu/pub/gopher/Unix/go4gw2.02.tar.Z
Included with the go4gw package is a Gopher gateway to Archie. In many ways, the Archie-Gopher gateway is superior to using an Archie client. The largest benefit is that this gateway first checks the load average on the various Archie servers. Then it
issues the query to the Archie server with the lightest load, which usually will give you the quickest response.
Also, this gateway returns the items in a nice Gopher menu. You can then retrieve an item by just selecting the item from the menu instead of having to look at the Archie results and then issue the appropiate FTP commands.
It should be noted, however, that this does not make Brendan Kehoe's popular Archie C client obsolete. The C client has a few extra features that a guru may use (priorities, for example). However, in all honesty, the key reason it is not obsolete is
that the Archie-Gopher gateway depends on it being installed on the server for the gateway to work. You can acquire the Archie-Gopher gateway from the following:
ftp://ftp.cs.widener.edu/pub/archie.tar.Z
Also included with the go4gw gateway package is a gateway to NetFind. NetFind enables you to find people's e-mail addresses on the Internet. If you have used the UNIX NetFind client, the only advantage you will find with using the NetFind-Gopher gateway
is that it is a little prettier. To use this gateway, you will need to acquire the NetFind package from the following:
ftp://ftp.cs.colorado.edu/pub/cs/distribs/netfind/netfind4.6.tar.Z
Also, you will need to regularly download the updates of the NetFind data from this address:
ftp://ftp.cs.colorado.edu/pub/cs/distribs/netfind/seeddb.tar.Z
Whois is another gateway that is included with the go4gw software. This gateway provides an easy-to-use mechanism to query the various Whois databases, such as the InterNIC's.
NeXT machines came with Webster Dictionary servers automatically. It was an obvious step for Gopher to include support for them. This gateway is also part of the go4gw package. Due to licensing reasons, however, you can legally use Webster Dictionary
servers only at your own site. It is generally a violation of copyright law to use a server belonging to another site.
Previous sections discuss AFTP as a method for using FTP within Gopher. AFTP is fairly recent and available only in the UMN UNIX software. Previous to that, the g2ftphack gateway was used for a similar function. The g2ftphack gateway is included with
the go4gw package. It works when the user types in the FTP server he or she wishes to connect to. The gateway then FTPs to there and presents the user with the files on the FTP as a menu. It is still useful for users of clients that do not have the AFTP
feature built in.
Several different Gopher to Usenet News gateways exist. Included with the go4gw package is g2nntp. This particular package allows whole newsgroups or just individual articles to be listed. Another one of the packages is gonntp
(from Louisana State University), which is available at the following address:
ftp://boombox.micro.umn.edu/pub/gopher/incoming/gonntp-exec-LaTech.tar.Z
gonntp has been modified to use INN's (InterNetNews) XHDR command. This version is called gonnrp and is quite a bit faster than the original gonntp. It can be found at the following:
ftp://boombox.micro.umn.edu/pub/gopher/Unix/gopher-gateways/gonnrp
All of the gateways treat each Usenet News article as a Gopher item. Many users want to use the Gopher purpose newsreader, but it is not good at that. The real purpose of these gateways is to include some information from Usenet News, along with other
information on the same topic.
X.500 is a complex directory service system that fits the whole world into one massive heirarchical framework. The Gopher-X.500 gateway software is known as go500gw. It makes X.500 looks like Gopher menus, items, and searches. Unfortunately, this
gateway is, at times, a little slow. The software is available from the following address:
ftp://mojo.ots.utexas.edu/pub/src/go500gw.c
SQL (Structured Query Language) databases such as Sybase and Oracle can be interfaced with Gopher through a gateway. The SQL gateway can turn Gopher commands into SQL commands. Some of the SQL functionality is lost in the process, but much of it still
exists. The gateway can be acquired from the following:
ftp://boombox.micro.umn.edu/pub/gopher/Unix/gopher-gateways/gophersql
Z39.50 is a protocol used by the library community to exchange bibliographic records. It will be an increasingly important facility on the Internet over the next few years. Right now, almost all library users have to telnet to various libraries, login,
and then use that site's user interface. It requires a lot of effort on the part of the user to learn all these different user interfaces. Instead of that, the user can use a Z39.50 client program, which will talk to the various libraries. The user needs
to know only one user interface.
Gopher has one of the first usable gateways to Z39.50. It is available from
ftp://boombox.micro.umn.edu/pub/gopher/Unix/gopher-gateways/go4zgate
The installation takes some time and is a little difficult. Also, you must be running Gopher+ on both the server and the client to use the Z39.50 gateway, because it uses fill-out forms.
Also, it should be noted that the Z39.50 protocol is still in the process of enhancement, so you should periodically check for new versions of the gateway that support some of the Z39.50 features coming along. One of the most important features that
should be coming down the pike is holding information so you can see if the library actually has the book you are looking for on the shelves.
go4gw has a few more gateways included that we have not discussed, all of which seem to be used infrequently. A gateway to an areacode server is available. The geography gateway enables you to get information on cities, latitudes, longitudes,
populations, evaluations, and other such information. In addition, there is a gateway to SNMP (Simple Network Management Protocol). The SNMP gateway is, in general, useful only to network adminstrators, because it is a system for monitoring and managing
networks.
Finally, go4gw is extendable. Therefore, if you need a gateway that does not exist and you know Perl, it is easy to add one to go4gw.
Gmail is very different than any other gateway discussed so far. All these other gateways are for the user viewing information external to Gopher. In contrast, Gmail is a gateway that allows people to post documents into a UNIX Gopher server via an
e-mail message. This is useful for people who are on a different platform from your Gopher server and do not know how to use UNIX. Also, it is often the easiest way to post an item if you are on a different UNIX machine, because it will place and set up
the item correctly automatically for you.
The Gmail adminstrator installs Gmail and then sets up a security file. In this file, the adminstrator can control who can post to which Gopher menu. The security checking is weak and based on e-mail return addresses, but it does have a fallback line of
defensive. If someone does forge a message that gets posted, Gmail always sends a copy of any posted message automatically to the person who it is supposedly from and, depending on the configuration, others as well. On a forged e-mail message, this does
not go to the forger but to the person who is allowed to post, and that person will know that they did not send the message. Therefore, the hacker really has no chance for his work to go undetected.
Along with Gmail is an associated program called Gcal. Gcal is for managing a Gopher-based, calendar-of-events system via e-mail. Gcal enables multiple people to add items into the calendar of events also. Gmail can be acquired from
ftp://boombox.micro.umn.edu/pub/gopher/Unix/GopherTools/gmail1.01.shar
A couple of newer, stable beta releases with major improvements have came out since 1.01, which is what is listed here. If you can not find a later release on boombox and you want it, you will need to ask Prentiss Riddle, the primary author of Gmail, by
sending him e-mail at riddle@is.rice.edu.
Previously, it was stated that Gopher Forms required the ASK block facility and Gopher+. This is true if you want to use the officially supported way of doing forms in Gopher. Well, of course, there is another way to do forms through a gateway. This is
useful for people who are not running Gopher+ servers.
The forms gateway package is called GoForm and is available as
ftp://boombox.micro.umn.edu/pub/gopher/Unix/GopherTools
GoForm works by having the user telnet to a specific port. On this port is a GoForm server, which is the form. Each form requires its own port and that GoForm server be running. This may sound painful, but it works quite a bit better than it sounds.
Also, in any case, it is really your only clean option of doing forms in Gopher without having to use Gopher+.
While the Gopher protocol and system do not lend themselves to security problems, some of the implementations of Gopher have had some security holes. Also, even with software that has no security holes, bad security practices on the part of the Gopher
adminstrator can lead to security problems.
An important good practice is to keep track of current security discussions. Security-related discussions involving Gopher may occur on comp.security.announce, cert-request@cert.org, or gopher-announce@boombox.micro.umn.edu.
The only Gopher clients and servers with known security problems are the UMN UNIX Gopher clients and servers. Any version before 1.13, and any version between 2.0 and 2.012 inclusive, has known and serious security problems. These version numbers apply
to both the client and the server code.
However, it is generally in your best interest to use the latest version of these programs whenever possible. The authors are currently in the process of rewriting significant portions of the code to greatly reduce the possibility of a security hole
being present. The changes mainly involve screening user input going to the client and information from the server that could cause a security problem on the client end.
The largest remaining security problem with the client side of Gopher, as well as with any other information retrieval system, is that some document types are insecure by their nature and should be viewed only with great care. One example is PostScript.
It is possible to imbed file system commands in a PostScript document. If you retrieve such a PostScript document with Gopher to view it, Gopher will pass the document to your PostScript interpreter. At that point, it is up to your PostScript viewer
whether or not to process these commands. If it does, you could lose files—or worse. On the positive side, to my knowledge this has never been exploited, but that does not mean it will not happen sometime in the future.
The server has a much greater potential for security mistakes being made. First, the Gopher server should never be run as root or any other account that has special system privileges. Also, you need to be sure that any shell or Perl scripts you write
and put on your Gopher server are secure. If they are Perl scripts, you may want to run them using Taintperl instead of normal Perl. Taintperl makes sure that you never pass user input to a shell without really meaning to. These kinds of programming
problems have been the most frequent cause of security problems in the Gopher system to date.
The standard way to install the Gopher server is so that it runs under a chroot environment. The basic concept here is that the server can see only a tiny fraction of the files on the server machine. These files are the only ones it needs to operate.
Many other files that could cause serious security problems for your server if viewed or changed will not be in the chroot environment to cause problems. However, the chroot environment is difficult to work with in many ways. Gopher lets you run in a
normal (non-chroot) environment also. This option should be used only with extreme care and only when absolutely necessary because it greatly increases your potential security risks.
Also, many of the Gopher gateways have suffered at various times from security problems. Older versions of the Veronica server and go4zgate, for example, had some serious security problems. Both of those have been fixed, but others may not have.
 Note: There aren't really version numbers that signify fixed vs. unfixed. In both cases, there is a version that may or may not have the hole.
Note: There aren't really version numbers that signify fixed vs. unfixed. In both cases, there is a version that may or may not have the hole.
Another good practice is to always log your Gopher transactions, which will enable you to have an audit trail if problems occur. In addition, this is a useful tool in debugging some misconfigurations of your or other Gopher servers.
In the gopherd.conf file on the UMN UNIX Gopher server are some access: lines that specify what access the Gopher server allows to specific hosts and/or domains. Some example access: lines look like the following:
access: default !read,!browse,!search,!ftp access: .utdallas.edu read,browse,search,ftp access: .metronet.com read,browse,search,!ftp access: .unt.edu !read,browse,!search,!ftp
In this example, by default, access on the Gopher server is granted to nobody. The default rule applies to anyone who is not covered by a specific rule. Next, people who are on machines in the .utdallas.edu domain are given have full access to the
Gopher server.
Users in the .metronet.com domain have full access, except for FTP. I have found this to be an extremely useful feature. The Gopher server acts as an FTP gateway for Gopher clients. From my experience, the impact of this on the server can be very
negative. The FTP gateway is resource-intensive and has been prone to bugs. In almost all cases, you will want to allow local users to use the gateway, but as far as remote users go, it needs some careful thought.
Finally, a neighboring university (the University of North Texas, or unt) is given browse access only to the server. The effect is that UNT users see the menus on the server, but they do not have access to read any item on the Gopher server. This
practice is known as teasing and at GopherCon 94 was recognized as a bad practice to use. It is annoying to the users of the Gopher system.
Search is the last option. It controls whether or not the user can access any search item or WAIS database that resides on the server.
Some Gopher adminstrators want to run public access Gopher clients so that they do not have to assign accounts to all users who need to run Gopher. This can be a huge security hole if it is not done absolutely correctly.
First, you need to install special versions of tn3270, telnet, more, and other viewers that have been checked for security holes and do not allow access to a shell. Many of these can be found at
ftp://boombox.micro.umn.edu/pub/gopher/Unix/GopherTools/securegopher.tar.Z
It is critical to make sure that only these can be run by the public access client. Otherwise, you are effectively giving everybody access to a UNIX prompt on your public access machine.
Another important step is to run the Gopher client with the -s flag. This flag disables many Gopher features such as printing, saving files, and choosing viewers.
The public-access Gopher client needs to be in its own account, which should not be used for anything else. In addition, it should not run a shell of any type or call the Gopher startup script or program that you want to use immediately upon login.
Also, the account should be configured so that the user is logged out immediately upon exiting Gopher.
From its beginnings, Gopher was developed based on the concept of open access to information. IP-address-based security options were soon added, because it is useful to restrict access to certain types of information. However, Gopher still did not have
a way to identify a user on a multiuser host machine or handle a user who moved around to different machines at different times.
Because the Gopher server is stateless, this made things more difficult. Obviously, a system that asks you for a password on every transaction is too painful to use. For this reason, UMN created the AdmitOne authenication schemes. When using AdmitOne,
the client and the server run through the password transaction once and then use authenicated tickets to keep the user authenicated with the server for the remaining transactions.
This section does not delve into the depths of the authenication system. Some security experts have criticized AdmitOne as being light-weight authenication; it does make it harder for hackers to break in and steal the data they want, but a
determined effort will succeed. The critics say that if you go to the trouble of implementing a light-weight security scheme, you might as well use a heavy-weight system such as Kerberos instead. The defenders of AdmitOne say that light-weight has its
place by being easy to implement and protecting some sensitive but noncritical data; the amount of effort to break in is greater than the value of the data itself. You can make your own decision.
Many WWW supporters feel that Gopher is useless and needs to be replaced by the Web. However, as many users know, the Web requires too much hardware horsepower to be a solution for everyone. To effectively use the Web, you need a fast CPU,
VGA-resolution or higher graphics, and a fast Internet connection (faster than 14.4K). Meanwhile, Gopher was designed to work on very low-end machines with 2400-baud SLIP connections. Over the next few years, Gopher will continue to have a place just
because the Web is too resource-intensive (though the Web will probably eventually supercede Gopher's role).
Some Gopher supporters believe that the best future option is not the unstuctured chaos of hypertext documents currently on the Web. They feel that Gopher's role is to provide a table of contents for the world of Internet information.
People are now working on 3-D interfaces to Gopherspace. It is said that the CPU horsepower now available with Pentium and PowerPC chips means that it can be done effectively. The implementation plan is that the Gopher+ protocol would remain the same;
only minimal data would be sent across the network.
All the graphical displays would be calculated and shown by the client. Therefore, it would be possible for different clients to have different graphical interfaces. In the current prototype, the item types are shown via shapes. All kinds of interesting
ideas, like beaten-down paths for highly-used items, are being discussed. Some of us who suffer from motion sickness have our doubts as to the benefits of a 3-D interface; it may be bad for health reasons.
Another part of the eventual 3-D interface will be interactive communication facilities, so that users of the Gopher system will be able to interact with each other while looking for information. The many useful applications for this facility include
the ability of one person to show another person where information is in Gopherspace.
In addition to indexing FTP sites, Archie will soon be indexing Gopher sites too. The key difference between Archie and Veronica will be that Veronica indexes everything unless specifically told not to. Archie will index only what it is told to index.
![]()
![]()
![]()
![]()
![]()
{kind=link}